Introduction
Every major AI coding tool — Claude Code, Codex, Cursor, Windsurf, OpenCode — invents its own
project folder: .claude/, .codex/, .cursor/, .windsurf/. Each one stores the same kind of
knowledge: which agents exist, what the project rules are, which skills and MCP servers matter.
The result is the same context duplicated under many vendor names.
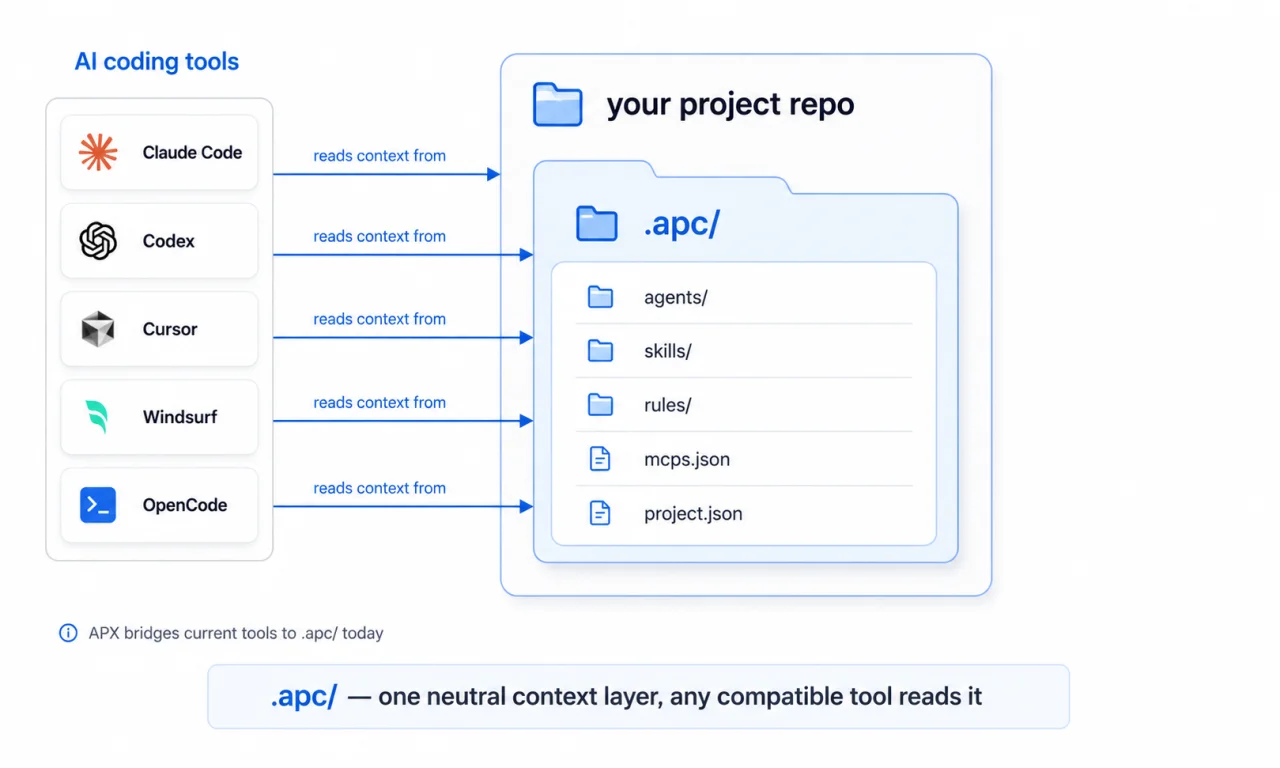
APC, Agent Project Context, is a proposal for those tools to converge on one neutral name: .apc/.
The mission is not for developers to maintain yet another folder. The mission is for tool vendors
to adopt .apc/ as their native default, replacing their own branded directories. APX is the
reference runtime that enables this today, before native vendor support exists.
APC answers one narrow question:
What should every compatible agent know when it enters this project?
APC is not an agent runner, database, daemon, IDE plugin, or chat transcript store. It is the project-owned context layer that any compatible tool can read before it starts work.
The split APC enforces
Agent systems usually mix three different things:
- project contract: durable rules, skills, architecture notes, MCP expectations
- agent definitions: roles, activation descriptions, model inheritance, skills
- runtime state: sessions, conversations, tool outputs, caches, private runtime memory, provider threads
- private configuration: API keys, tokens, local paths, personal preferences
APC keeps the project contract and structured agent definitions in the repository. Runtime state and private configuration stay outside the repository, owned by the IDE, CLI, daemon, or user machine that produced them.
Goals
- reduce duplicated context across IDE-specific folders
- keep durable context close to the codebase
- make context inspectable, reviewable, and versionable
- provide a neutral layer for agents, IDEs, and developer automation
- prevent raw sessions and private tool output from being committed by accident
- let different runtimes consume the same project contract without sharing sensitive transcripts
Canonical directory
The canonical repository directory is:
.apc/Typical APC content includes:
- project metadata
- agent definitions
- rules, including optional path-scoped rules
- durable project plans
- skills
- curated project memory, only when safe to share
- optional MCP configuration hints, without secrets
Typical APC content does not include:
- raw chat sessions
- provider conversation threads
- tool call logs
- API keys or bearer tokens
- OAuth tokens, private headers, or credentials in MCP URLs
- unreviewed auto memories
- private scratch plans
- personal preferences for one IDE
Relationship to existing tooling
APC is designed to coexist with:
AGENTS.md- IDE-specific folders
- local or hosted agent runtimes
- MCP registries and tool servers
The goal is not to forbid tool-specific configuration. The goal is to stop copying the same project
meaning into .claude/, .cursor/, .codex/, .opencode/, and other runtime-specific places.
See One Context, One Name for the full rationale.
Each IDE or runtime may still keep its own sessions and transcripts. That separation is intentional: sessions often contain private prompts, credentials pasted by mistake, production data, or customer details. APC should expose durable project meaning, not every conversation that happened near the project.
APC can be the source for shared project meaning while runtimes keep projection files they need.
For example, .apc/rules/*.mdc can be projected into .cursor/rules/, and .apc/mcps.json can be
projected into .cursor/mcp.json or another runtime-specific MCP config. Those projections should
not become secret stores or raw session stores.